Broadcom’s Jericho 4: Next-Generation AI Chip for Ultra-Fast Data Center GPU Connectivity
Broadcom has recently released a next-generation AI chip designed specifically to optimize ultra-fast connectivity between data center GPUs, a breakthrough that supports massive AI model training and infrastructure scaling. This new chip, named Jericho4, represents a critical advancement in networking technology tailored for the explosive data demands of large-scale artificial intelligence workloads. It enables unprecedented bandwidth, security, and low-latency communication essential for distributed AI computing environments across multiple data centers.
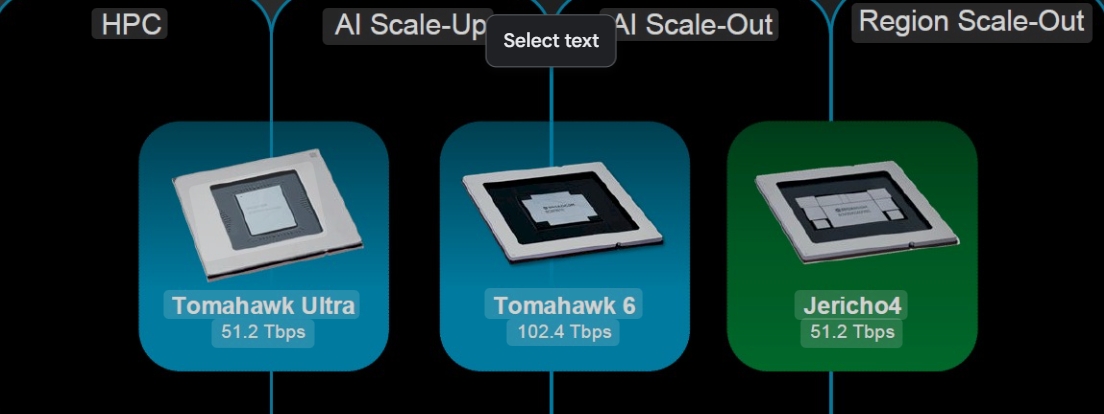
The Jericho4 chip stands out by its ability to connect over one million XPUs (AI accelerators like GPUs) spread across multiple data centers. This scalability breaks through traditional limits that confined AI infrastructure within single physical locations, thus enabling the formation of geographically distributed AI supercomputers. The chip supports 102.4 terabits per second of Ethernet switching capacity, providing roughly four times the information throughput of its predecessor, the Tomahawk 6. This ultra-high bandwidth is vital to handle the continuous, massive data exchanges necessary to train and run large AI models efficiently.
Ad Content
Broadcom’s Jericho4 uses advanced technologies such as high-bandwidth memory (HBM) to manage traffic congestion and large data volumes in real-time. It supports a range of Ethernet-based network topologies and includes enhanced routing and congestion control features—collectively branded as Cognitive Routing 2.0. These features intelligently manage traffic patterns typical of AI workloads, such as fine-tuning, reinforcement learning, and large language model reasoning, ensuring data flows seamlessly even in demanding multi-GPU environments.
Security is another cornerstone of the Jericho4 design, incorporating MACsec encryption on every port at full line-rate. This ensures data moving between data centers is protected against interception without compromising speed or performance, a growing priority as AI services become ubiquitous and cybersecurity risks escalate.
The chip also supports both copper and optical connectivity options with co-packaged optics technology to reduce latency and power consumption. This flexibility allows cloud providers and hyperscalers to customize network setups based on physical constraints and performance needs, optimizing cost and energy efficiency.
Jericho4’s compatibility with the Tomahawk 6 switch and the Tomahawk Ultra family offers a comprehensive networking solution for AI infrastructures. Together, they cover interconnectivity requirements within single racks, across racks, and between multiple data centers, forming a unified, open, and interoperable ecosystem optimized for AI workloads.
This innovation is critical as AI models grow larger and require distributing computations across thousands or hundreds of thousands of GPUs. Without such specialized networking chips, GPUs often operate below capacity due to bandwidth bottlenecks awaiting data transfer. By drastically improving AI cluster interconnects, Broadcom’s chip enables faster model training, higher GPU utilization, and scalability extending beyond traditional data center limits.
Broadcom’s achievement not only supports immediate AI infrastructure needs but also positions industries to handle the future complexity and scale of AI applications, driving advancements in cloud computing, machine learning research, and real-time AI services.
Enjoyed this post?
Subscribe to Evervolve weekly for curated startup signals.
Join Now →